2018 年 5 月 22 日,在微软举办的 “新一代人工智能开放科研教育平台暨中国高校人工智能科研教育高峰论坛” 上,微软亚洲研究院宣布,携手北京大学、中国科学技术大学、西安交通大学和浙江大学四所国内顶尖高校共建新一代人工智能开放科研教育平台,以推动中国人工智能领域科研与教育事业的发展。作为由微软亚洲研究院为该平台提供的三大关键技术之一,Open Platform for AI(OpenPAI)也备受瞩目。
事实上,随着人工智能技术的快速发展,各种深度学习框架层出不穷,为了提高效率,更好地让人工智能快速落地,很多企业都很关注深度学习训练的平台化问题。例如,如何提升 GPU 等硬件资源的利用率?如何节省硬件投入成本?如何支持算法工程师更方便的应用各类深度学习技术,从繁杂的环境运维等工作中解脱出来?等等。
为了解决这些问题,微软亚洲研究院和微软(亚洲)互联网工程院基于各自的特长,联合研发、创建了 OpenPAI,希望为深度学习提供一个深度定制和优化的人工智能集群管理平台,让人工智能堆栈变得简单、快速、可扩展。
为什么要使用 OpenPAI?
● 为深度学习量身定做,可扩展支撑更多 AI 和大数据框架
通过创新的 PAI 运行环境支持,几乎所有深度学习框架如 CNTK、TensorFlow、PyTorch 等无需修改即可运行;其基于 Docker 的架构则让用户可以方便地扩展更多 AI 与大数据框架。
● 容器与微服务化,让 AI 流水线实现 DevOps
OpenPAI 100% 基于微服务架构,让 AI 平台以及开发便于实现 DevOps 的开发运维模式。
● 支持 GPU 多租,可统筹集群资源调度与服务管理能力
在深度学习负载下,GPU 逐渐成为资源调度的一等公民,OpenPAI 提供了针对 GPU 优化的调度算法,丰富的端口管理,支持 Virtual Cluster 多租机制,可通过 Launcher Server 为服务作业的运行保驾护航。
● 提供丰富的运营、监控、调试功能,降低运维复杂度
PAI 为运营人员提供了硬件、服务、作业的多级监控,同时开发者还可以通过日志、SSH 等方便调试作业。
● 兼容 AI 开发工具生态
平台实现了与 Visual Studio Tools for AI 等开发工具的深度集成,用户可以一站式进行 AI 开发。
部署OpenPAI
1、前提准备
我准备了四台机器,三台用于集群,一台用于部署集群。
- Ubuntu 18.04 。
- 每台服务器都有静态 IP 地址,并确保服务器可以相互通信。
- 确保服务器可以访问互联网,特别是 Docker Hub 或其镜像服务器。 在部署过程中需要拉取 OpenPAI 的 Docker 映像。
- 确保 SSH 服务已启用,所有服务器使用相同的用户名、密码,并启用 sudo 权限。
- 确保 NTP 服务已启用。
- 建议不提前安装 Docker 组件,如果已安装,确保 Docker 版本高于 1.26。
- OpenPAI 会保留部分内存和 CPU 资源来运行服务,须确保服务器有足够的资源来运行机器学习作业。 详情参考cpu&memory requirement(根据实际部署来看,worker节点至少32G内存,否则在部署到hadoop run时会出现不符合最小配置的`ERROR)。
- OpenPAI 的服务器不能提供其它服务。 OpenPAI 会管理服务器的所有 CPU、内存和 GPU 资源。 如果服务器上有其它的服务负载,可能导致资源不足而产生各种问题。
ps:节点上尽可能的纯净,它会帮你安装docker等相关服务,甚至显卡驱动是通过container来挂载给集群使用,当然也可以自己安装最佳显卡驱动,在配置的时候更改默认配置,详情见后续配置修改。
错误排查:部署driver-one-shot时,如果是在安装过显卡驱动的节点上可能会出现启动不起来,日志显示nvidia错误,一种方法是加入黑名单:
1 | > vim /etc/modprobe.d/blacklist-nouveau.conf |
2、部署
| nodes | ip/allocation | roles |
|---|---|---|
| node-dev | 192.168.1.100 | dev-box |
| node00 | 192.168.1.200 core: 8 memory: 64G gpu: Titan XP *2 |
master worker |
| node01 | 192.168.1.201 core: 8 memory: 32G gpu: 1080Ti *2 |
worker |
| node02 | 192.168.1.202 core: 8 memory: 32G gpu: 1080Ti *1 |
worker |
node-dev用于运行官方提供的dev-box镜像部署集群,由于可能会涉及到docker和系统环境的影响,所以官方不推荐在集群中运行dev-box
1、配置文件
1 | > sudo docker run -itd \ |
进入容器后到达/pai目录,拷贝并修改模板配置文件
1 | > cp deployment/quick-start/quick-start-example.yaml deployment/quick-start/quick-start.yaml |
然后生成配置文件
1 | > python paictl.py config generate -i /pai/deployment/quick-start/quick-start.yaml -o ~/pai-config -f |
此处我们可以修改后面三个文件
1 | > vim services-configuration.yaml |
1 | > vim layout.yaml |
1 | > vim kubernetes-configuration.yaml |
2、开始部署
启动k8s环境
1 | > cd /pai |
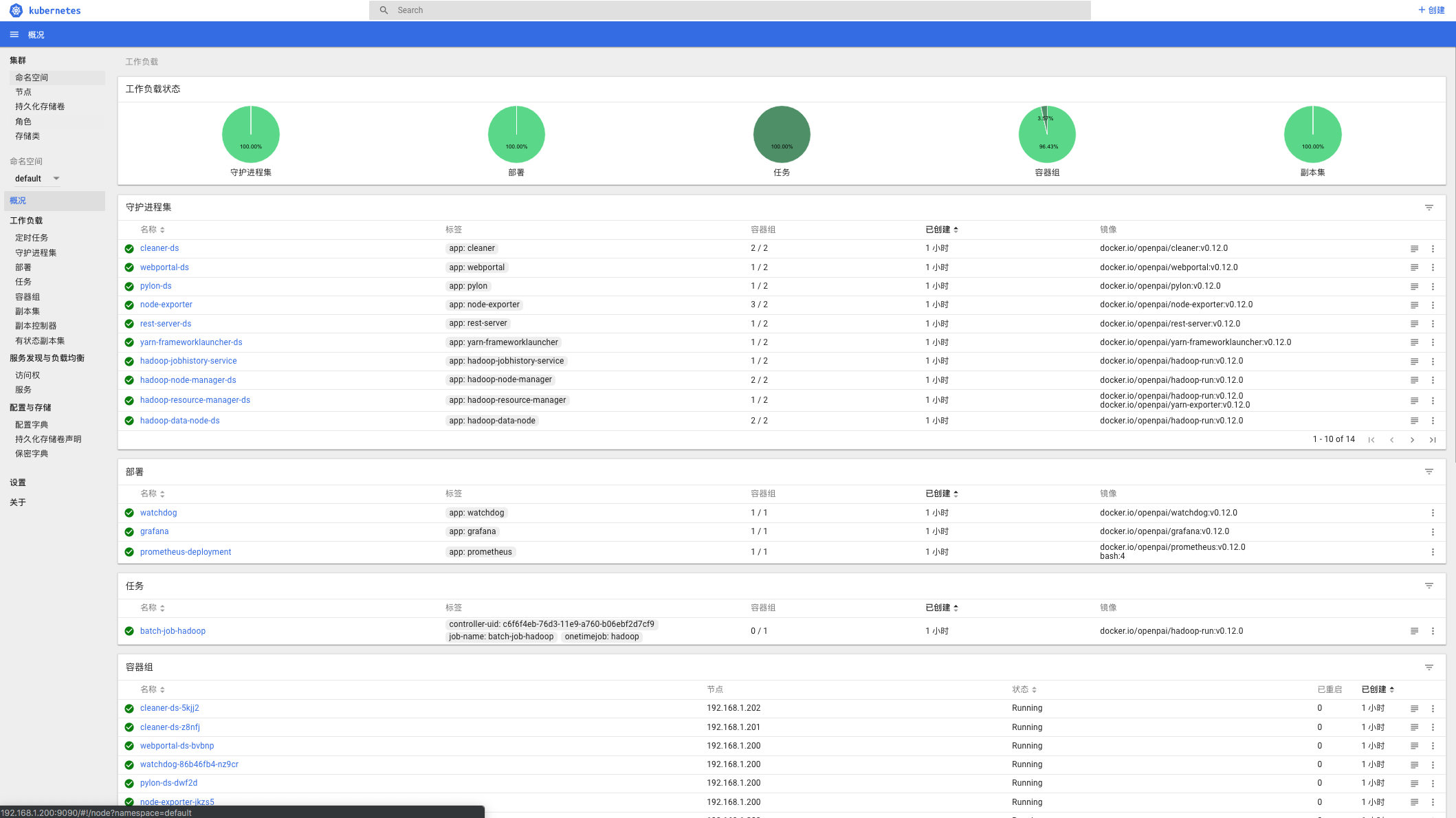
等待下载镜像,全部通过后可以在http://master_ip:9090查看k8s_dashboard
一切安好后上传pai的配置到k8s集群中
1 | > python paictl.py config push -p ~/pai-config |
如果在之前配置文件没有设置cluster_id的话,此时会让你设置一个id。
后续可以通过
1 | > python paictl.py config get-id |
来获取你设置的cluster_id
配置上传完毕,即可正式开始部署开启pai
1 | python paictl.py service start(stop、delete) |
接下来就是漫长的下载镜像–>部署镜像–>报错–>修复–>重启–>成功
需要注意的是,排查报错后重启服务时,可能需要删除openpai和k8s生成的本地文件,比较重要的有/var/etcd存储k8s配置和集群内信息(pods、daemonset等)、/etc/kubernetes/存储k8s在各个节点上的配置文件(.yml)、/datastorage某些时候重启容器会出现这里面目录创建不了的问题,可能是权限,删除目录重启服务即可。
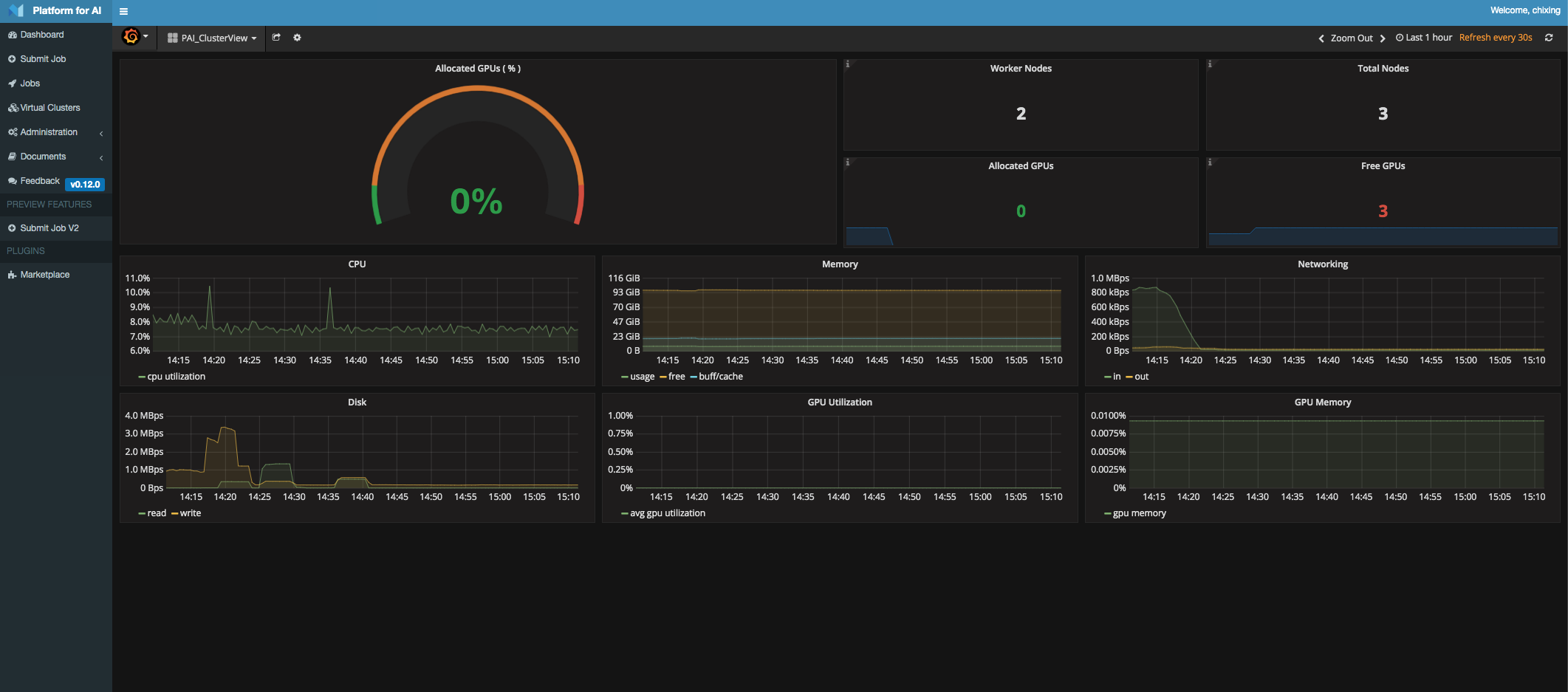
部署完成后即可在dashboard上查看健康情况。
3、验证
http://master_ip:9286/virtual-clusters.html会打开openpai的dashboard,输入配置文件中的账号密码即可打开本次项目