1. 服务降级和限流
https://zhuanlan.zhihu.com/p/61363959
2. redis string类型的底层实现
https://juejin.im/post/5d71d3bee51d453b5f1a04f1
3. redis的持久化方式
https://juejin.im/post/5b70dfcf518825610f1f5c16
4. aqs和cas,死锁检测
https://www.jianshu.com/p/12192b13990f
https://zhuanlan.zhihu.com/p/61221667
5. 设计题,涉及到并发和数据库
6. string类型为什么不可变
安全、效率(内存地址)
7. 二叉树找出距离最大的两个节点
1 | # Definition for a binary tree node. |
8. mvcc的实现
[file:///D:/%E5%AD%A6%E4%B9%A0%E8%B5%84%E6%96%99/01-%E4%B8%93%E6%A0%8F%E8%AF%BE/06-MySQL%E5%AE%9E%E6%88%9845%E8%AE%B2/02-%E5%9F%BA%E7%A1%80%E7%AF%87%20(8%E8%AE%B2)/08%E4%B8%A8%E4%BA%8B%E5%8A%A1%E5%88%B0%E5%BA%95%E6%98%AF%E9%9A%94%E7%A6%BB%E7%9A%84%E8%BF%98%E6%98%AF%E4%B8%8D%E9%9A%94%E7%A6%BB%E7%9A%84%EF%BC%9F.html](file:///D:/学习资料/01-专栏课/06-MySQL实战45讲/02-基础篇 (8讲)/08丨事务到底是隔离的还是不隔离的?.html)
9. 间隙锁
间隙锁(Gap Locks)(重点)
间隙锁是封锁索引记录中的间隔,或者第一条索引记录之前的范围,又或者最后一条索引记录之后的范围。
产生间隙锁的条件(RR事务隔离级别下;):
- 使用普通索引锁定;
- 使用多列唯一索引;
- 使用唯一索引锁定多行记录。
10. 链表实现加法
1 | # Definition for singly-linked list. |
11. linux命令 查硬盘 端口 AWK
查硬盘:
统一磁盘整体情况,包括磁盘大小,已使用,可用df -h
具体查看文件夹的占用情况:du --max-depth=1 -h,计算文件夹大小du -sh /usr/
端口:
-i后不加端口,展示所有打开的端口
1 | # lsof -i:8000 |
或者使用这个
1 | netstat -ntlp //查看当前所有tcp端口 |
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
- grep 更适合单纯的查找或匹配文本
- sed 更适合编辑匹配到的文本
- awk 更适合格式化文本,对文本进行较复杂格式处理
面经:
作者:yayakah
链接:https://www.nowcoder.com/discuss/427290
来源:牛客网
1.用python的装饰器写一个单例模式。
1 | import time |
2.python和C++、Java的区别是什么?python有编译吗?
有编译,但仍然是解释型语言,编译成pyc文件其实是pycodeobject的持久化文件
3.python的args和kwargs、metaclass、反射。
先定义metaclass,就可以创建类,最后创建实例,metaclass允许你创建类或者修改类,一般用在ORM框架中
反射:
1 | 通过字符串映射object对象的方法或者属性 |
4.讲一讲go协程和线程。go的并发模型、goroutine。
5.Go的内存模型、垃圾回收。
6.get和post有什么区别?put和post呢?幂等性是什么?
https://app.yinxiang.com/shard/s39/nl/25071110/97dfcfa0-3f45-4017-a89a-c76e8e25e2e2
语义上来说put是幂等的,post不是
幂等性:一次请求和重复的多次请求对系统资源的影响是一致的
7.tcp三次握手、流量控制、字节流。
流量控制是为了控制发送方发送速率,保证接收方来得及接收。
接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
tcp面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块
8.https的加密过程,详细讲一下。
9.谈下你对nginx和uwsgi的理解、为什么要用wsgi?
1.使用的代理一共有两个,nginx和uwsgi,先说明一下,如果不用nginx一样可以访问web项目,使用nginx的目的是为了安全和负载均衡。配置了nginx做前端代理,uwsgi作后端代理的服务器(这里所说的前后端都是相对的位置,并无实际含义),在处理来自Internet的请求时,要先经过nginx的处理,nginx把请求再交给uwsgi,经过uwsgi才能访问到项目本身。
2.没有nginx而只有uwsgi的服务器,则是Internet请求直接由uwsgi处理,并反馈到web项目中。nginx可以实现安全过滤,防DDOS等保护安全的操作,并且如果配置了多台服务器,nginx可以保证服务器的负载相对均衡。
而uwsgi则是一个web服务器,实现了WSGI协议(Web Server Gateway Interface),http协议等,它可以接收和处理请求,发出响应等。所以只用uwsgi也是可以的。
server和application的规范在PEP3333中有具体描述,要实现WSGI协议,必须同时实现web server和web application,当前运行在WSGI协议之上的web框架有,Flask, Django。
WSGI其实就是一个规范,他规范了Python程序和服务器之间的通信。对于Apache/Nginx等等服务器来说,只要支持WSGI规范,就可以保证所有(兼容WSGI的)Python程序能运行;对于Python程序或者框架来说,只要兼容WSGI,就可以保证能在所有(支持WSGI的)服务器上运行
10.docker的image、layer、container分别讲下?Linux中namespace是怎么实现的,底层的数据结构是什么?
多层layer组成一个image,运行中的image就是container

1 | struct task_struct { |
11.B和B+树,B+树的搜索次数、为什么不用二叉树。
B+树相对于B树有一些自己的优势,可以归结为下面几点。
- 单一节点存储的元素更多,使得查询的IO次数更少,所以也就使得它更适合做为数据库MySQL的底层数据结构了。
- 所有的查询都要查找到叶子节点,查询性能是稳定的,而B树,每个节点都可以查找到数据,所以不稳定。
- 所有的叶子节点形成了一个有序链表,更加便于查找。
所以我们要减少IO次数,对于树来说,IO次数就是树的高度,而“矮胖”就是b树的特征之一,它的每个节点最多包含m个孩子,m称为b树的阶,m的大小取决于磁盘页的大小。
12.kafka是push还是pull?kafka和nsq的区别,什么场景下该用哪个?partition的数据如何保存到硬盘?
produce(生产者)push到breaker(调度者),cusomer(消费者)从breaker来pull,没有消息时cusomer阻塞状态,不会频繁轮询,阻塞时间一般100ms
对比
存储
NSQ 默认是把消息放到内存中,只有当队列里消息的数量超过–mem-queue-size配置的限制时,才会对消息进行持久化。
Kafka 会把写到磁盘中进行持久化,并通过顺序读写磁盘来保障性能。持久化能够让Kafka做更多的事情:消息的重新消费(重置offset);让数据更加安全,不那么容易丢失。同时Kafka还通过partition的机制,对消息做了备份,进一步增强了消息的安全性。
推拉模型
NSQ 使用的是推模型,推模型能够使得时延非常小,消息到了马上就能够推送给下游消费,但是下游消费能够无法控制,推送过快可能导致下游过载。
Kafka 使用的拉模型,拉模型能够让消费者自己掌握节奏,但是这样轮询会让整个消费的时延增加,不过消息队列本身对时延的要求不是很大,这一点影响不是很大。
消息的顺序性
NSQ 因为不能够把特性消息和消费者对应起来,所以无法实现消息的有序性。
Kafka 因为消息在Partition中写入是有序的,同时一个Partition只能够被一个Consumer消费,这样就可能实现消息在Partition中的有序。自定义写入哪个Partition的规则能够让需要有序消费的相关消息都进入同一个Partition中被消费,这样达到”全局有序“
13.consul的原理有了解过么?服务发现、健康检查、多数据中心分别说下?
14.Z字层次遍历二叉树。
层次遍历加个条件即可
1 | from collections import deque |
15.三数之和
1 | class Solution: |
16.合并K个排序链表。
合并2个排序链表+分治法
1 | class Solution: |
作者:yayakah
链接:https://www.nowcoder.com/discuss/425251
来源:牛客网
2.数据库相关:
a. order by 索引
https://c.isme.pub/2016/12/21/sql-performance/
b. 聚簇&非聚簇索引
聚集索引。表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
非聚集索引。表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
总结一下:聚集索引是一种稀疏索引,数据页上一级的索引页存储的是页指针,而不是行指针。而对于非聚集索引,则是密集索引,在数据页的上一级索引页它为每一个数据行存储一条索引记录。
c. 最左匹配原则
其实官方文档已经解释的非常详细了, 总结关于最左匹配的解释, 那其实只有这么 几句话:
1.按照文档, 更准确的说法应该是最左前缀原则, 即如果你创建一个联合索引, 那 这个索引的任何前缀都会用于查询, (col1, col2, col3)这个联合索引的所有前缀 就是(col1), (col1, col2), (col1, col2, col3), 包含这些列的查询都会启用索 引查询.
2.其他所有不在最左前缀里的列都不会启用索引, 即使包含了联合索引里的部分列 也不行. 即上述中的(col2), (col3), (col2, col3) 都不会启用索引去查询.
注意, (col1, col3)会启用(col1)的索引查询
d.组合索引
联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
e.加索引有什么原则
https://www.jianshu.com/p/107e5bdf4148
3.redis 缓存:
redis mysql双写:mysql写完删除redis,不更新因为生成缓存存在复杂查询,不如直接删了,做好防止突然雪崩即可
a.并发情况下,一个前端请求过来时,redis发生了什么?
b.缓存的刷新策略
https://juejin.im/post/5af5b2c36fb9a07ac65318bd
4.http有哪些头部?详细介绍一下Cookie。
https://blog.csdn.net/YLBF_DEV/article/details/50266447
https://www.jianshu.com/p/51fbe0dd8282
5.为什么要用kafka?kafka中的broker是什么?kafka是如何实现分区的?
http://www.louisvv.com/archives/2408.html
6.docker镜像和容器有什么区别?为什么要用docker?Linux namespace讲一下?Linux cgroup的层级结构讲一下?docker daemon是啥?发现docker daemon响应突然变慢了,如何排查?
Linux CGroup全称Linux Control Group, 是Linux内核的一个功能,用来限制,控制与分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)
- Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting: 一些审计或一些统计,主要目的是为了计费。
- Control: 挂起进程,恢复执行进程。
https://coolshell.cn/articles/17049.html
https://www.cnblogs.com/menkeyi/p/10941843.html
Docker daemon是Docker最核心的后台进程,它负责响应来自Docker client的请求,然后将这些请求翻译成系统调用完成容器管理操作。该进程会在后台启动一个API Server,负责接收由Docker client发送的请求;接收到的请求将通过Docker daemon内部的一个路由分发调度,再由具体的函数来执行请求。
7.python相关知识,迭代器、生成器、装饰器?metaclass、args、kwargs。Flask与wsgi是如何交互的?Flask源码读过么?Flask的IO多路复用用在了什么地方?
8.算法题,奇数升序偶数降序,返回升序
- 奇偶拆开
- 倒序奇数链表
- 有序合并
1 | class Node: |
9.算法题,LRU。
- 有序字典
1 | from collections import OrderedDict |
- 双向链表+hash表
链表存储缓存的内容(key, val),hash存储{key: d_node}双链表
删除缓存时,从双链表尾端获取key来hash中删除
hash保证O(1),双链表保证有序
1 | class DListNode: |
10.算法题,最大的岛屿面积。
等同于岛屿数量,只是求多个岛屿中1最多的
1 | class Solution: |
作者:Mac🐱
链接:https://www.nowcoder.com/discuss/419718
来源:牛客网
一面4.26
小哥全程微笑,态度很好
python
列表推导式
sort怎么实现
TimSort算法是一种起源于归并排序和插入排序的混合排序算法,设计初衷是为了在真实世界中的各种数据中可以有较好的性能。
基本工作过程是:
1.扫描数组,确定其中的单调上升段和严格单调下降段,将严格下降段反转;
2.定义最小基本片段长度,短于此的单调片段通过插入排序集中为长于此的段;
3.反复归并一些相邻片段,过程中避免归并长度相差很大的片段,直至整个排序完成,所用分段选择策略可以保证O(n log n)时间复杂性,空间复杂度O(n)
可以看到,原则上TimSort是归并排序,但小片段的合并中用了插入排序。
sort与sorted区别
sort()是列表自带的函数,通过比较大小来排序,参数是key和是否倒序,
sorted()是python内建的高级函数,可对一切可迭代对象进行排序
两者都可以给key传一个函数或者匿名函数来排序
sort()原地排序,sorted()返回一个可迭代对象,原对象不变
操作系统
内存的堆和栈
栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。
区别和联系:
1.申请方式
堆是由程序员自己申请并指明大小,在c中malloc函数 如p1 = (char *)malloc(10);
栈由系统自动分配,如声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
2.申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会 遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内 存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大 小,系统会自动的将多余的那部分重新放入空闲链表中。
3.申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结 构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在WINDOWS下,栈的大小是2M(也有的说是1M,总之是 一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
4.申请效率的比较:
栈由系统自动分配,速度较快。但程序员是无法控制的。
堆是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
体会:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
中断,怎么实现
什么是中断?
CPU 暂停正在执行的程序转而去执行处理该事件的程序
为什么需要系统中断、异常、调用?中断不会使效率变低吗?
- 计算机运行时 内核是被信任的第三方
- 只有内核才能够执行特权指令
- 方便应用程序调用
中断会不会使效率变低是要取决于看中断的角度 中断虽然打断了当前操作的执行 但是却正是因为中断使得系统能够并发运行
系统本质上是一个死循环 但是死循环做不了什么大事 而系统运行的目的是为了等候某些事情的发生 系统是被动的 因此也可以说 操作系统是中断所驱动的
中断的分类
- 外部中断 也称之为硬件中断
- 可屏蔽中断 使用 INTR 信号线通知CPU
- 不可屏蔽中断 使用 NMI 信号线通知CPU
![img]()
- 内部中断 又称软中断和异常
- int 8位立即数
- int3 调试断点指令
- into 中断溢出指令
- bound 数组索引越界
- ud2 未定义指令
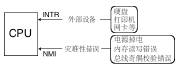
除了 int 8位立即数以外 其它都可以称作是异常
中断、异常和系统调用区别
- 系统调用(system call):应用程序主动向操作系统发出的服务请求
- 异常(exception): 非法指令或其他原因导致当前指令执行失败后的处理请求
- 中断(handware interrupt):来自硬件设备的处理请求
每个中断或异常与一个中断服务例程(Interrupt Service Routine ISR) 相关联
Linux 系统调用并没有使用调用门 而是直接使用int 0x80中断 来完成系统调用
计网
TCP与IP区别
TCP传输层,IP网络层,一般IP处于TCP下方,给TCP字节添加上IP头后传输到对应目的ip地址,TCP会找到对应端口
TCP怎么保证可靠
首先是三次握手保证建立正确的一对一连接,超时重传机制,发送报文段后一定时间没有收到确认就重新传送,超时时间由往返时间进行计算得出,滑动窗口保证一次处理一部分有序报文段,直到这些报文段都收到确认(接收端都收到报文段)才会移出滑动窗口
拥塞控制机制
TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
发送方需要维护一个叫做拥塞窗口(cwnd)的状态变量
慢开始和拥塞避免
发送的最初执行慢开始,令 cwnd = 1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 …
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。
快重传和快恢复
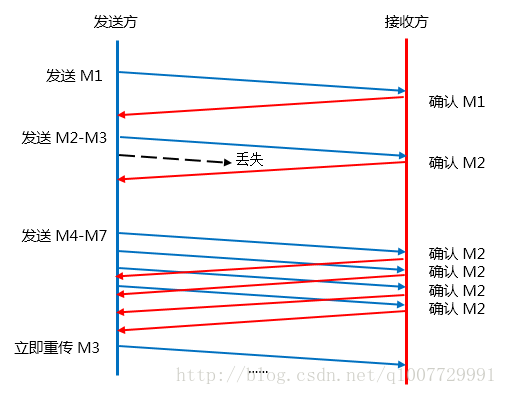
连续收到M2的确认ACK,无需等待确认超时,直接重传
快恢复不同于拥塞避免,一旦出现超时重传,或者收到第三个重复的 ack 时(快重传),TCP 会把慢启动门限 ssthresh 的值设置为 cwnd 值的一半,同时 cwnd = ssthresh,而不是从1开始
代码题
逆序输出数组中奇数的平方
找不到具体描述
判断链表是否有环
不仅判断是否有环,还返回环的下标
1 | # Definition for singly-linked list. |
lc海岛,01矩阵那个,算有几个岛
深度dfs
1 | class Solution: |
二面4.28
还是个小哥,我不会的时候很耐心的引导
HTTP包格式
Accept: text/html text/plain image/jpeg text/css application/json
HTTP1.1,1.0,2区别
HTTP1.1,1.0:
- 缓存方面增加ETag来多种策略控制缓存
- 断电续传的功能header中的range,返回码206
- 增加HOST头,用于应对nginx反向代理多个服务器
- 长连接:在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟
- 增加了多个错误返回码
- HTTP 1.1还允许客户端不用等待上一次请求结果返回,就可以发出下一次请求
2.0和1.1:
- 二进制分帧:HTTP/1.1的头信息是文本(ASCII编码),数据体可以是文本,也可以是二进制;HTTP/2 头信息和数据体都是二进制,统称为“帧”:头信息帧和数据帧;
- 多路复用(双工通信):通过单一的 HTTP/2 连接发起多重的请求-响应消息,即在一个连接里,客户端和浏览器都可以同时发送多个请求和响应,而不用按照顺序一一对应,这样避免了“队头堵塞”。HTTP/2 把 HTTP 协议通信的基本单位缩小为一个一个的帧,这些帧对应着逻辑流中的消息。并行地在同一个 TCP 连接上双向交换消息。
- 数据流:因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。HTTP/2 将每个请求或回应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流ID,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流,ID一律为奇数,服务器发出的,ID为偶数。数据流发送到一半的时候,客户端和服务器都可以发送信号(
RST_STREAM帧),取消这个数据流。HTTP/1.1取消数据流的唯一方法,就是关闭TCP连接。这就是说,HTTP/2 可以取消某一次请求,同时保证TCP连接还打开着,可以被其他请求使用。客户端还可以指定数据流的优先级。优先级越高,服务器就会越早回应。 - 首部压缩,一方面,头信息压缩后再发送(SPDY 使用的是通用的DEFLATE 算法,而 HTTP/2 则使用了专门为首部压缩而设计的 HPACK 算法)。;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
- 服务端推送
TCP序号机制,是否按序发按序收
http://xstarcd.github.io/wiki/shell/TCP_ACK.html
python生成器
1 | L = [x * x for x in range(10)] |
自己定义的类要实现len()怎么做
__len__()魔法函数
协程
async和await
协程: 协程,又称微线程,纤程,英文名Coroutine。协程的作用,是在执行函数A时,可以随时中断,去执行函数B,然后中断继续执行函数A(可以自由切换)。但这一过程并不是函数调用(没有调用语句),这一整个过程看似像多线程,然而协程只有一个线程执行.
协程由于由程序主动控制切换,没有线程切换的开销,所以执行效率极高。对于IO密集型任务非常适用,如果是cpu密集型,推荐多进程+协程的方式。
内存的堆与栈
前有答案
redis消息队列
列表实现lpush(),消费者阻塞等待blpop()
短链接怎么实现
客户端请求:
DNS服务获取ip地址,请求到短链接服务,服务获取到短链接后跟的地址(6位),进行62(AZ+az+0~9)进制转10进制得到数据库中的id,查询是否相等后,进而301永久重定向到长链接中
服务端生成:
首先查询数据库中是否存在该长链接,存在就返回短链接地址,
不存在就插入一条自增的数据,存入长链接,获取该自增id,进行10进制转62进制,得到6位短地址(不够6位就在前面填几个0对应的62进制),存入数据库中
可以存在62^6次方个短地址
介绍虚拟内存,怎么从磁盘拿需要的部分
https://zhuanlan.zhihu.com/p/53004596
局部性原理:
时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次被执行;如果某个数据被访问过,不就之后该数据很有可能再次被访问。(因为程序中存在大量的循环)
空间局部性:一旦程序访问了某个存户单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)。
时间局部性和空间局部性统称为局部性原理。
页面置换方式进入到内存,与最近最久未使用的页面进行替换
数据库的最左匹配原则,为什么
辅助索引中的排序是靠第一个索引字段来的
首先会对复合索引的最左边,也就是索引中的第一个字段进行排序,在第一个字段排序的基础上,在对索引上第二个字段进行排序,其实就像是实现类似order by 字段1,字段2这样的排序规则,那么第一个字段是绝对有序的,而第二个字段就是无序的了,因此一般情况下直接只用第二个字段判断是用不到索引的,这就是为什么mysql要强调联合索引最左匹配原则的原因。
RPC,微服务(不会,小哥给我解释了一番)
代码题
每次可以走[1,3,5]步,问走到100有多少种方法
leetcode 377. 组合总和 Ⅳ
1 | class Solution: |
三面 5.7 许愿HR面
操作系统文件描述符
fd(io复用中使用的)
维基百科:文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。
对称加密非对称加密
公钥|公钥+私钥
http|https
AES|RSA
进程和线程
最近整理了自己的笔记, 发一下自己的理解, 还请大方之家赐教
PS 不涉及多核情况下的讨论
本质上都是对 Task 的执行规划
- 你CPU快过IO设备, 人类作为统治阶级要压榨你, 不让你闲着, 于是一个任务(程序) 对应一个进程就出来了. 你CPU要雨露均沾的执行这些程序
- 然后呢? 人们发现 程序 还有很多可以细分的任务, 于是 多线程的设计方式出来了. 多线程的实现方案实在是太成熟了, 以至于大部分操作系统的实现是一个进程至少有一个执行线程, 于是各种桌面软件服务器软件冒出来了
- 接着呢? 人们发现 像 Web Server 这种东西, 完全是靠IO嘛, Thread Per Message 完全可以一波流, 但创建和销毁 Thread 成本依旧很高, 于是协程这种东西也就又开始流行了.
下面是比较详细的对比, 因为知乎不支持表格, 就贴 OneNote 的截图了
 )
)

进程间通信方法,哪个最快
共享内存
常见进程间通信方式的比较:
管道:速度慢,容量有限
消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题。
信号量:不能传递复杂消息,只能用来同步
共享内存区:能够很容易控制容量,速度快 ,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了一块内存的。
HTTP状态码
https://www.runoob.com/http/http-status-codes.html
redis与memcached区别,为什么redis用的多
Memcache
Memcache可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS,适用于最大程度扛量
只支持简单的key/value数据结构,不像Redis可以支持丰富的数据类型。
无法进行持久化,数据不能备份,只能用于缓存使用,且重启后数据全部丢失
Redis
支持多种数据结构,如string,list,dict,set,zset,hyperloglog
单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
支持持久化操作,可以进行aof及rdb数据持久化到磁盘,从而进行数据备份或数据恢复等操作,较好的防止数据丢失的手段。
支持通过Replication进行数据复制,通过master-slave机制,可以实时进行数据的同步复制,支持多级复制和增量复制.
首先支持多种数据结构、可备份、高可用、易扩展
微服务 RPC 为什么不用HTTP
一般会觉得HTTP协议携带大量无用的header,导致请求字节会比较大,所以一般使用自定义的rpc框架,基于tcp传输。良好的rpc调用是面向服务的封装,针对服务的可用性和效率等都做了优化。单纯使用http调用则缺少了这些特性。成熟的rpc库相对http容器,更多的是封装了“服务发现”,”负载均衡”,“熔断降级”一类面向服务的高级特性。
多线程fork之后进程是否是多线程
不是,除了发起fork()的线程外,其它都不会有
会存在死锁问题:之前多线程对一个资源(所有资源、栈、内存空间、fd等复制)上锁,上锁的线程没了,也就不能释放锁,所以会死锁。解决方法是fork()前获取所有锁,新进程中释放
rand4()求rand6()
1 | def rand6(): |
不均匀硬币模拟均匀概率
- 两次均为正面:p * p
- 第一次正面,第二次反面:p * (1 - p)
- 第一次反面,第二次正面:(1 - p) * p
- 两次均为反面:(1 - p) * (1 - p)
所以只要第二次和第一次不同即可
代码:包含最多k个不同字符的最长子串
Given a string, find the length of the longest substring T that contains at most k distinct characters.
For example,
Given s = “eceba” and k = 2,
T is “ece” which its length is 3.
1 | class Solution(object): |
作者:Japs0n
链接:https://www.nowcoder.com/discuss/236551?type=2&order=0&pos=12&page=1&channel=-1&source_id=1_2
来源:牛客网
算法题
一面:
lc里最长上升子序列的变形题。
1
2
3
4
5
6
7
8
9
10
11class Solution:
def lengthOfLIS(self, nums: List[int]) -> int:
if not nums:
return 0
size = len(nums)
dp = [1 for _ in range(size)]
for i in range(1, size):
for j in range(i):
if nums[j] < nums[i]:
dp[i] = max(dp[i], dp[j] + 1)
return max(dp)
实现输入英文单词联想的功能
前缀树
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.trie = {}
def insert(self, word: str) -> None:
"""
Inserts a word into the trie.
"""
tree = self.trie
for w in word:
if w not in tree:
tree[w] = {}
tree = tree[w]
tree['#'] = None
def search(self, word: str) -> bool:
"""
Returns if the word is in the trie.
"""
tree = self.trie
for w in word:
if w not in tree:
return False
tree = tree[w]
if '#' in tree:
return True
else:
return False
def startsWith(self, prefix: str) -> bool:
"""
Returns if there is any word in the trie that starts with the given prefix.
"""
tree = self.trie
for w in prefix:
if w not in tree:
return False
tree = tree[w]
return True
# Your Trie object will be instantiated and called as such:
# obj = Trie()
# obj.insert(word)
# param_2 = obj.search(word)
# param_3 = obj.startsWith(prefix)
二面:
矩阵旋转,要求空间复杂度O(1)
1
2
3
4
5
6
7
8
9
10
11
12class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
for i in range(len(matrix)):
for j in range(len(matrix[0])):
if j < i:
matrix[i][j], matrix[j][i] = matrix[j][i], matrix[i][j]
for i in range(len(matrix)):
matrix[i].reverse()
无序的数组的中位数。要求时间复杂度尽可能的小
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import heapq
def get_mid(nums):
min_heap = []
max_heap = []
for num in nums:
if len(min_heap) == len(max_heap):
heapq.heappush(max_heap, -heapq.heappushpop(min_heap, -num))
else:
heapq.heappush(min_heap, -heapq.heappushpop(max_heap, num))
if len(min_heap) == len(max_heap):
return (max_heap[0] - min_heap[0]) // 2
else:
return max_heap[0]
x = [1, 3, -1, -3, 5, 3, 6, 7]
print(get_mid(x))
计算机网络
tcp 怎么保证数据包有序
http://xstarcd.github.io/wiki/shell/TCP_ACK.html
发送和接收缓冲区,发送端字节流序号以及接收端的确认号(=序号(100)+长度(100)+1=201)
tcp 和 udp 的异同
1. 对比
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
tcp 怎么保证可靠性
等同tcp 怎么保证数据包有序
tcp 中 拥塞避免 和 流量控制 机制
[https://github.com/CyC2018/CS-Notes/blob/master/notes/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%20-%20%E4%BC%A0%E8%BE%93%E5%B1%82.md#tcp-%E5%8F%AF%E9%9D%A0%E4%BC%A0%E8%BE%93](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机网络 - 传输层.md#tcp-可靠传输)
流量控制主要是修改接收端的滑动窗口(在tcp头的窗口字段设置),从而影响发送端的发送效率
拥塞避免就是慢开始会有一个上限(一次发送报文段的阈值),当慢开始(从1开始每次发送报文翻倍)到达这个阈值后,不是翻倍,而是+1,如果出现超时,则使这个阈值设为当前发送数的一半,并且重新开始慢开始
PS:快重传和快恢复都是针对丢失报文段而不是网络堵塞,因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
tcp 四次挥手的详细解释
- A 发送连接释放报文,FIN=1。
- B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
- 当 B 不再需要连接时,发送连接释放报文,FIN=1。
- A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
- B 收到 A 的确认后释放连接。
四次挥手之后为什么还要等待2msl
2 MSL(最大报文存活时间)
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
- 确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
- 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
浏览器从输入网址到显示出网页的全过程
https://segmentfault.com/a/1190000017184701
滑动窗口机制的原理和理解
https://blog.csdn.net/wdscq1234/article/details/52444277
Https 原理和实现
SSL是由网景公司发明的,后来由于应用广发,IETF就把SSL进行标准化,并把标准化后的SSL改名为TLS。所以,TLS可以说是SSL的加强版,两者是同一个东西的不同阶段。
https://netsecurity.51cto.com/art/201912/607179.htm#topx
cookie和session的区别是什么
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
操作系统
进程和线程的区别
见上进程和线程
进程切换与线程切换
进程切换分两步
1.切换页目录以使用新的地址空间
2.切换内核栈和硬件上下文。
对于linux来说,线程和进程的最大区别就在于地址空间。
对于线程切换,第1步是不需要做的,第2是进程和线程切换都要做的。所以明显是进程切换代价大
Linux中五种IO模型
https://juejin.im/post/5c725dbe51882575e37ef9ed#heading-8
阻塞和非阻塞主要针对调用者是否等待结果,同步和异步主要是针对被调用者是否立刻返回结果
如何实现一个同步非阻塞的请求
就是阶段1的时候用户进程可选择做其他事情,通过轮询的方式看看内核缓冲区是否就绪。如果数据就绪,再去执行阶段2。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好, 此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程, 循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好, 再拷贝数据到进程,进行数据处理。需要注意,第2阶段的拷贝数据整个过程,进程仍然是属于阻塞的状态。
实现进程同步的机制有什么
[1. 临界区](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机操作系统 - 进程管理.md#1-临界区)
[2. 同步与互斥](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机操作系统 - 进程管理.md#2-同步与互斥)
[3. 信号量](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机操作系统 - 进程管理.md#3-信号量)
[4. 管程](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机操作系统 - 进程管理.md#4-管程)
信号量的实现机制
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
- down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
- up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
共享锁和排他锁
共享锁【S锁】
又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
排他锁【X锁】
又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
实现一个读写锁
http://xiaorui.cc/archives/2384
1 | import threading |
设计一个无锁队列
http://xiaorui.cc/archives/4626
1 | # xiaorui.cc |
协程的原理
async和await
协程: 协程,又称微线程,纤程,英文名Coroutine。协程的作用,是在执行函数A时,可以随时中断,去执行函数B,然后中断继续执行函数A(可以自由切换)。但这一过程并不是函数调用(没有调用语句),这一整个过程看似像多线程,然而协程只有一个线程执行.
协程由于由程序主动控制切换,没有线程切换的开销,所以执行效率极高。对于IO密集型任务非常适用,如果是cpu密集型,推荐多进程+协程的方式。
数据库
索引是什么
索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
为什么要用B+树(B+树的优缺点)
优点
- 单次请求涉及的磁盘IO次数少(出度d大,且非叶子节点不包含表数据,树的高度小);
- 查询效率稳定(任何关键字的查询必须走从根结点到叶子结点,查询路径长度相同);
- 遍历效率高(从符合条件的某个叶子节点开始遍历即可);
缺点
B+树最大的性能问题在于会产生大量的随机IO,主要存在以下两种情况:
- 主键不是有序递增的,导致每次插入数据产生大量的数据迁移和空间碎片;
- 即使主键是有序递增的,大量写请求的分布仍是随机的;
B+树中叶子节点间的指针有什么用
方便区域查询,不需要中序遍历
聚簇和非聚簇索引的区别
见上b. 聚簇&非聚簇索引
非聚簇索引的查询都要回表吗?
? 应该是辅助索引查询都需要回表吗:不是 覆盖索引不需要
B+树 和 AVL树 B树 二叉搜索树有什么区别
AVL和二叉搜索树都是二叉的,高度会很高,且不利于磁盘查找
B+树相对于B树来说只有叶子节点存储数据,且叶子结点间有指针相连(链表)
where 中 or 和 and 对于索引的使用有什么区别
用or分割开的条件,如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
杂项
这一部分和项目比较相关。基本上项目中有什么或者面试官想到什么问什么问了很多但是不通用。就只写一点。
GIL
是什么
全局解释器锁,每个CPU在同一时间只能执行一个线程
为什么会有
CPython 内存管理不是线程安全的,因此需要 GIL 来保证多个原生线程不会并发执行 Python 字节码。
- 单线程情况下更快。
- 瓶颈在于 I/O 的多线程环境下更快。
- CPU 耗时操作发生在 C 库调用上时更快。
- 编写 C 扩展会更容易:除非你手动指定,否则不会发生 Python 线程切换的问题。
- 封装 C 库变得更容易,因为不需要考虑线程安全问题。如果该库不是线程安全的,你只需要保证调用时 GIL 是锁定的。
有什么作用
https://zhuanlan.zhihu.com/p/20953544
怎么规避它对于并行的影响
多进程+协程
语言相关
Python 的 内存 管理 机制
讲一下Python GC的原理和 详细解释(分代,标记回收,内存划分)
Python中static_method 、 class_mathod 、和普通method有什么区别
迭代器和生成器有什么区别
如何构造一个生成器
作者:GithubOverFlow
链接:https://www.nowcoder.com/discuss/259363?type=2&order=0&pos=13&page=1&channel=-1&source_id=1_2
来源:牛客网
一面
聊项目(30分钟)
手撕代码,python协程实现一个生产者消费者模型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
对称加密非对称加密。
公钥|公钥+私钥
ORM。
sqlachemy
SQL 注入。
构造一个sql语句,后面加一个or 1=1等
短链接的原理。如t.cn如何映射到一个真正的域名。
见上
数据库ACID。
原子性、一致性、隔离性、持久性
Python 装饰器。
见上
剩下还有一些我不记得了,一面感觉更像一个简历面。
二面
重写与重载。
C++虚函数表,只有虚函数表的对象占据多少内存。
SSO原理。
对称加密非对称加密。
SSL原理。
TCP慢启动,客户端服务端滑动窗口大小如何协商。
HTTP keep-alive,管线化。
手撕代码,二叉树最近公共祖先。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def __init__(self):
self.public = None
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if not root:
return False
def helper(node):
if not node:
return False
mid = node == p or node == q # True or False
left = helper(node.left)
right = helper(node.right)
if mid + left + right == 2:
self.public = node
return mid or left or right
helper(root)
return self.public
Redis 数据结构。
什么样的列不适合建立索引。
- 很少被查询使用的字段
- text一类大容量的字段
- 值很少或者大量重复的字段(性别)
- 修改远大于读的字段
访问一个网页,响应很慢,从哪些方面排查问题?如何优化?
I/O多路复用与其他网络I/O模型的区别。
select、poll、epoll
进程与线程。
线程与协程。
爬虫适合用多进程还是多线程。
多线程:python GIL不会影响io密集处理,而且爬虫需要一个集中处理重复url问题等,新建进程会创建新的虚拟内存
不同线程的堆栈相同吗。
共享进程的局部堆,各自有栈
堆: 是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。
\栈:**是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是 thread safe的。每个C ++对象的数据成员也存在在栈中,每个函数都有自己的栈,栈被用来在函数之间传递参数。操作系统在切换线程的时候会自动的切换栈,就是切换 SS/ESP寄存器。栈空间不需要在高级语言里面显式的分配和释放。
C++内存分布。
Define与const。
情景题:某脚本同时处理一大堆文件,若脚本突然挂掉,如何判断处理到了哪些文件的哪些部分。
批量处理的时候记录处理到的行数
有许多八位数的电话号码,设计一个存储方案,用尽可能少的内存,达到比较高效的检索。
类似于布隆过滤器,位图二进制,一个0/1代表一个值是否存在
按Control-C,发生了什么。
中断信号
Tornado 为什么那么快。
Python items 和 iter-items的区别。
聊项目(20分钟)
作者:花落忆流年╮
链接:https://www.nowcoder.com/discuss/206371?type=2&order=0&pos=14&page=1&channel=-1&source_id=1_2
来源:牛客网
1.HTTP和RPC的区别
见上微服务 RPC 为什么不用HTTP
2.HTTP的常见方法,post与get差别,常见的请求头key-val对儿
3.后台报504错误,分析原因如何解决
504是网关获取后面服务信息超时,502是获取到无效的响应
4.数据库的索引问题,针对场景如何建立索引,为什么这么建立索引,怎样优化
mysql 。订单 order 实体有几个属性:产品(product_id)、下单日期(date)等,请设计 索引 实现下列需求并优化索引:
-—–
查询某个产品的所有订单。
查询某一天的所有订单。
查询有个产品最近一个月的所有订单。
-—-
5.编程题
对两个二进制字符串求十进制的和
6.设计一个HTTP服务,如何查询出订单量前十的商品,后台如何做
7.python的并发的问题

