Flask浅析系列
Flask浅析-request上下文Flask浅析-信号和Hook
理解Flask的request上下文
request是全局变量,但request的属性总是对应当前请求的值,这是如何做到的呢?同样的还有current_app。
request/app context是保存到栈里的,我们什么时候需要栈?很多人都有这样的疑问,有人在stackoverflow提了个很好的问题:What is the purpose of Flask’s context stacks?
初次接触Flask的人会觉得很神奇,即使是经验丰富的开发者也未必清楚其中的原因。Flask的文档对request context和app context的解释只会让不清楚实现细节的人更加迷惑。本文将试图从Flask的源码找到答案,向大家揭开这个黑魔法的面纱,并把这两个问题解释清楚。
以下的分析基于当前最新版的代码(0.13-dev)。
通过全局变量request访问当前请求的属性:
request只是一个代理
在同一个python进程中同时处理多个请求时,这里的同时是指并发,比如CherryPy使用多线程处理并发请求,Gunicorn为每个请求创建一个greenlet协程,那么request全局变量如何保存当前请求的属性呢? request当然不是一个普通的全局变量,它其实是代理类LocalProxy的对象,当访问request.path时会调用request的__getattr__魔术方法,该方法会正确地找到当前请求对应的request对象。
那么问题来了,LocalProxy类如何找到当前请求的对象?
request的内部机制
是时候看着源码讨论实现细节了,为了方便理解,以下忽略了无关的代码。
我们从获取request的属性开始跟踪代码的执行。 先看request全局变量定义的地方(flask/globals.py),
1 | def _lookup_req_object(name): |
LocalProxy充当代理类的作用,代码位于werkzeug/local.py,Werkzeug是Flask依赖的包,它是Flask的核心。
1 | class LocalProxy(object): |
可见,request全局变量总是对应_request_ctx_stack栈顶的request context的request属性。但还无法解释为什么访问request总是得到当前请求的值。
进一步看LocalStack的代码:
1 | class LocalStack(object): |
可见,LocalStack的栈保存在Local的stack属性上,它只是对Local的一层包装。
关键的地方在于Local
1 | # since each thread has its own greenlet we can just use those as identifiers |
Local的属性集(是一个dict)保存在内部的storage这个dict里,并以当前协程作为id或当前线程id作为key。因此,
不同协程或线程可以共用同一个Local全局变量而不产生冲突
。比如:
1 | # globally |
这就是前面提到的黑魔法。
有个疑问:如果当前环境安装了greenlet,但是使用多线程处理并发请求,那么根据代码,会使用greenlet的getcurrent作为当前请求的唯一id,这是否可行呢?答案是肯定的,greenlet的文档greenlet: Lightweight concurrent programming说每个线程都会有独立的主协程:
Greenlets can be combined with Python threads; in this case, each thread contains an independent “main” greenlet with a tree of sub-greenlets. It is not possible to mix or switch between greenlets belonging to different threads.
为什么需要LocalProxy和LocalStack
也许你会有这样的困惑,直接将context作为Local的属性或使context继承Local就可以达到并发请求公用一个全局变量的目的,那为什么需要LocalProxy和LocalStack呢?
使用LocalProxy的目的简单的说就是为访问提供便利。通过传入一个look up函数,可以代理任何感兴趣的对象,比如_request_ctx_stack.top实际返回的是当前请求的context对象,它的request属性对应当前的Request实例,request全局变量就是访问这个属性的代理,除了request还有session代理。
至于request context保存到栈里的目的Flask文档:The Request Context是这样解释的:
Because the request context is internally maintained as a stack you can push and pop multiple times. This is very handy to implement things like internal redirects.
然而实际上,Flask并没有内部重定向的方法,即一个view在内部访问另一个view,在第一个view中获取第二个view执行的结果。 Flask的redirect函数只不过是给客户端返回30x的状态码,浏览器会发送一个新的请求到指定的地址。redirect函数不会产生一个新的request context,当然也就不需要压栈,因此文档的解释有些不合道理。也许以后会支持这种功能,所以,使用栈来保存上下文能够为以后的功能扩展提供支持。
那么到底什么时候栈上会出现多个request context的情况呢?我无法构造出这种场景,似乎也没人给出过这样的例子。
不得不承认,这部分代码有些过于复杂了,也可能是某些地方我没有考虑到。
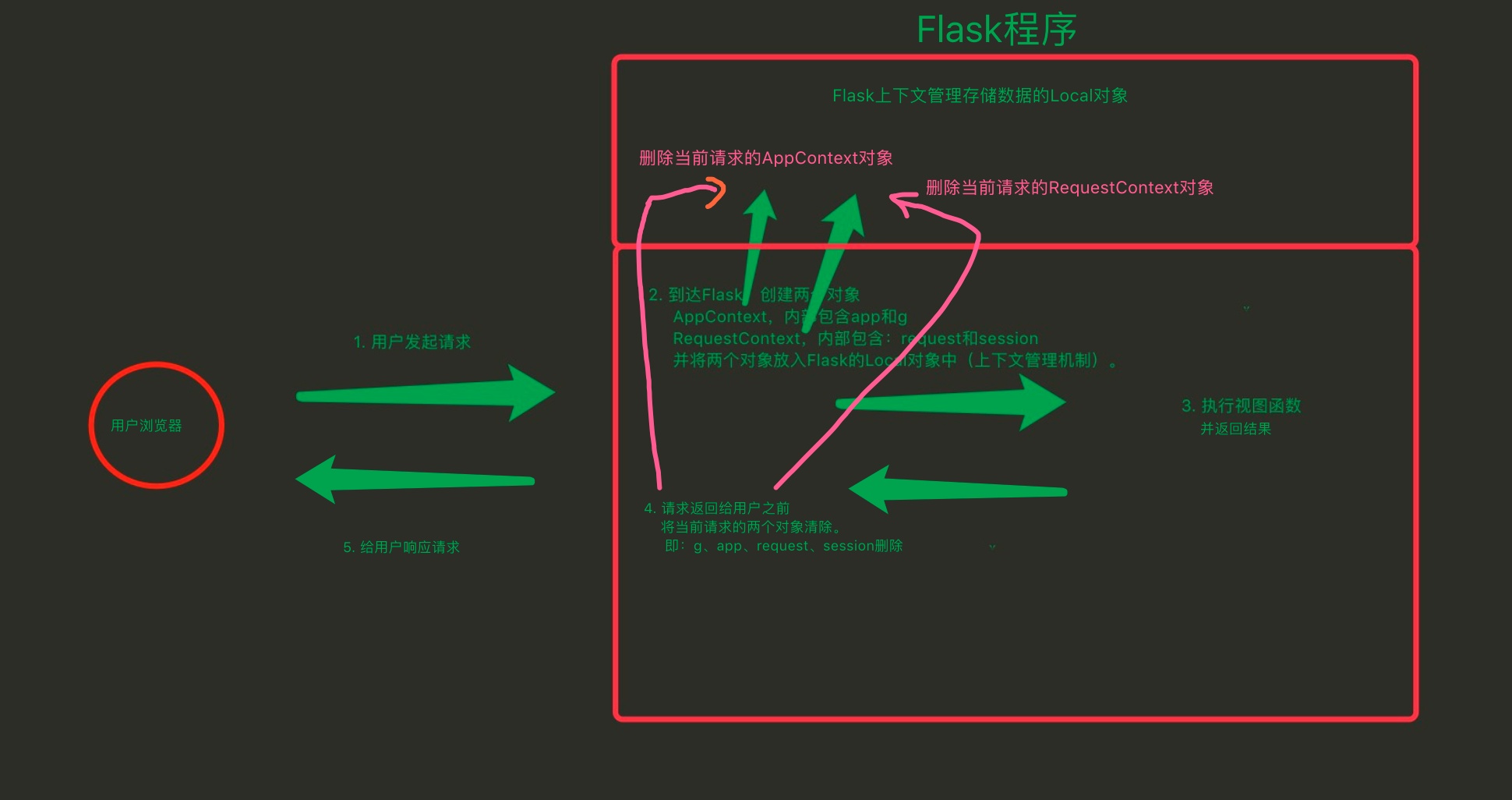
请求的生命周期
为了弄清楚request是如何被赋值的,来了解一下一次请求的生命周期。 一个Flask的实例就是一个wsgi app,对于每个请求wsgi server都会以如下方式调用这个app
1 | app(environ, start_response) |
因此它的入口就是call方法,以该方法为突破口,一个请求的从开始到结束的流程大致如下:
1 | ctx = self.request_context(environ) |
第1步创建了一个RequestContext对象,代表当前请求的上下文,内部包含Request和Session对象;
第2步将该context压栈,同时还创建了application context并压栈,可见每个请求都会有自己的app context,Flask的文档也对此进行了说明:
The application context is created and destroyed as necessary. It never moves between threads and it will not be shared between requests.
第3步是调用view function处理请求
第4步是弹出request和app ctx
request全局变量是对_request_ctx_stack的代理,但仅限于读,修改操作则是直接在_request_ctx_stack上完成,同样的还有_app_ctx_stack
以g为延伸了解上下文的Local